Data conversion with Redframes and Dataset
During active development, table schemas change frequently to correspond to up to date application requirements. Relational DBs are not that well at it as a lot of operations have to be made, you know it as migrations. Schemas not change only, but stored data as well.
Writing SQL code to get table schemas and data to aactual state is a subject that could be improved and moved to a higher, human friendly level.
Here i'm going to demonstrate a simple case of how i use the libraries Redframes , Dataset to transform the data and table and update them with fewer steps than i would make it with raw SQL.
Tools short description
Pandas is the well known library to work with data, but at particular cases it can be very tricky, unclear and complicated. Redrames is a wrapper that provides you with a set of intuitive, self-descriptive methods to solve problems more verbal but clear and excplicit, you know what i mean.
Dataset is a good abstraction over a relational DB making interaction with data NoSQL'ish. For example, such operations as creating many columns from a dataset, tables, deleting them are perfomed on the go. The main abstraction here is a dataset, not rows. You query a daset from DB, filter and modify it on an applicatioan level, and write it back. You don't have to pay time for an update query.
The Problem
Here is my small, demonstration problem, I write the different types of events to a DB. The event data properties are modified as long as an application grows. After the code of writing events has been updated i move to updating an according table and storeing data in it.
The sample of code and data state before a modification
event_tracker.emit(EventsEnum.card_edit.value, **input) # input sample field is `data_status`
| data_status |
| ----------- |
| labeled |
| labeled |
| labeled |
| labeled |
The sample and data state after
with event_tracker.context(CtxScopeDefault, {'name': EventsCtxEnum.page.value, 'value': PAGE_NAME}):
event_tracker.emit(EventsEnum.card_edit.value, **input)
| data_status | context_name | context_value |
| ----------- | -------------- | ------------- |
| labeled | null | null |
| labeled | page.filtering | null |
| labeled | page.labeling | null |
| labeled | page | labeling |
| null | page | filtering |
event_tracker.emit() creates new fields context_name, context_value on the go by using Dataset, no effort was paid for it. Internally the method dataset.Table.insert is invoked.
Solution
As of the new event tracking code the table has the following inconsistency:
context_nameisnull. It occured due to before code has changed some rows were exist.context_valueisnull. The same as above.context_nameis combined with a value. Have to be split up on to the name and value.
import dataset
import pandas as pd
import redframes as rf
db = dataset.connect('sqlite:///data/events.sqlite')
records = list(db['card.edit'].all())
rdf = rf.wrap(pd.DataFrame.from_records(records))
rdf.select(['data_status', 'context_name', 'context_value']).dedupe()
# data_status context_name context_value
# 0 labeled None None
# 1 None None None
# 2 None page.filtering None
# 3 None page.labeling None
# 4 None page labeling
updated_rdf = rdf.replace({'context_name': {None: 'page.labeling'}})\
.filter(lambda row: row['context_name'].isin(['page.filtering','page.labeling']))\
.mutate({'context_value': lambda row: row['context_name'].split('.')[1],
'context_name': lambda row: 'page'})
updated_rdf
# id timestamp context_name context_value
# 0 11 2022-11-26 13:46:54.522629 page labeling
# 1 12 2022-11-26 13:52:31.907136 page labeling
# 2 13 2022-11-27 11:43:14.530650 page filtering
# .. ... ... ... ...
# 424 457 2022-12-29 12:18:37.143143 page filtering
# 425 458 2022-12-29 15:42:34.203280 page labeling
# [426 rows x 12 columns]
The three steps are taken:
- Replaced all the
nullvalues - Filtered rows of combined context names
- Split those context names onto name and value
They are atomic, easy to read and understand, but a bit wordy.
Dataset is modified and ready to get written back to update the DB state.
# select the only fields to be updated in the DB
updated_records = rf.unwrap(
updated_rdf.select(['id', 'context_name', 'context_value'])
).to_dict('records')
db['card.edit'].update_many(updated_records, ['id'])
Explicitly updated the fields context_name, context_value by matching records in the DB to the dataset ones by id . If datatset_records would contain new fields they were created automatically.
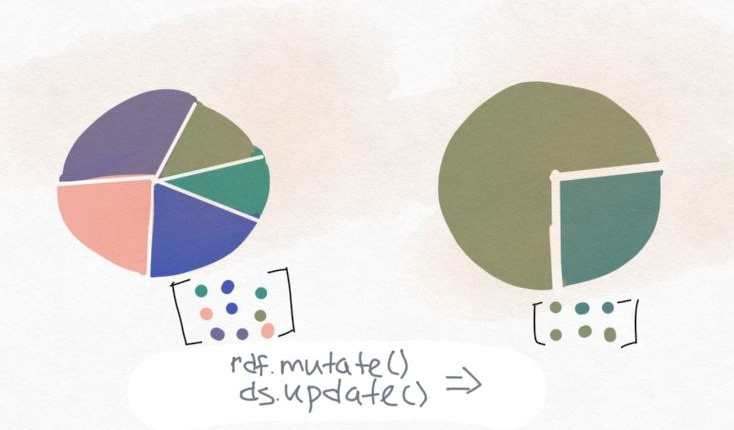
Visualize the solution
And for a better understanding of what i have done, both datasets values are visualized as pie charts at the before and after states.
The script to create the plots plots.py
| Before | After |
|---|---|
 |
 |